")
Corpus of Literary Modernity (Kolimo+)
Kolimo+ stands for ”Korpus der literarischen Moderne” (“Corpus of Literary Modernity”), where German “Moderne” refers to newer German literature as a whole, and thus a macro-period starting roughly around 1700 with the onset of the New High German (Neuhochdeutsch) language. It is a collection of German-language prose texts from around 1650-1930 with a focus on the middle of the 19th century and fictional texts. Its main application is for quantitative research in literary studies and linguistics. [mehr...]
Corpus of Literary Modernity (Kolimo+)
The Corpus of Literary Modernity (Kolimo+) is a corpus collection of full text German-language prose from around 1650-1930 with a temporal focus on the 19th century and genre focus on fictional prose. Originally it was built by Berenike Herrmann and Gerhard Lauer (2018) and published as “Kolimo Beta”.
Soon our originally narrow conception of literary “modernism around 1900“ was broadened the scale to Newer German Literature as a whole, starting with the onset of the New High German (Ger. Neuhochdeutsch) language. Kolimo+ comprises mostly fictional texts, but also nonfictional prose. Its intended use is for quantitative research in literary studies and linguistics. It was originally built for style analysis (‘literariness’, contrasting literary and nonliterary prose), but it can be used for many applications, including as a reference corpus for examination of specific corpora and collections, for finetuning language models, and training data for machine learning. As it covers a long time span, Kolimo+ can be a start for a diachronic analyses of literary history.
Overview
At the present moment, Kolimo+ comprises N=41,299 full texts (approx. N=510 mio tokens) by N=1,748 authors. Following the TextGrid genre classification, Kolimo+ includes n=34,941 prose texts (fictional prose), n=4,832 non-fiction texts, and n=1,526 texts classified as other. The corpus was aggregated and enriched from three sources: Deutsches Textarchiv, Projekt Gutenberg-DE, and TextGrid Repository. Duplicates were removed.
In cases where date of publication was not provided by the original data, the birth year of author gives an orientation. It was used in two different ways: (a) using the birth year of the author as an approximation for the date of publication (see Kolimo date in the chapter the XML-files), (b) a timeslot metadatum was created by putting the authors into 20-year spanning slots by birth date. The majority of the texts is by authors born between 1800-1839 as shown below:
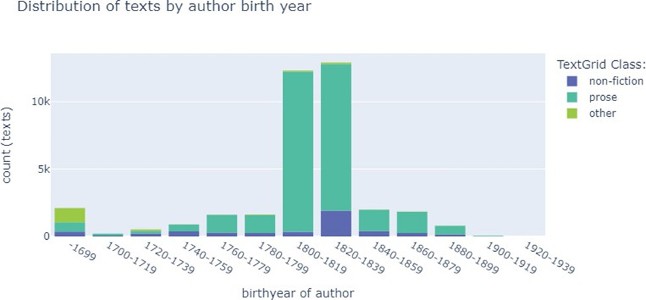
Each text is enriched with metadata about the text itself and its author. To ensure a unified and standardized metadata quality, the GND was used as a source and manually validated.
The corpus is international, but monolingual. It contains both original and translated German- language texts, but the majority is texts by German authors (n=928). Other German-language nationalities are also part of the corpus, but in a smaller capacity: n=36 Austrian authors and n=28 Swiss authors. There are also mixed nationalities: n=80 German-Austrian authors and n=49 Swiss-German authors.
A problem for determining the nationality of authors results from the GND. In the GND, the sequence of nationalities listed for authors is not normalized (e.g. Germany, Austria vs. Austria, Germany). The reason for this is the aggregation of several smaller data bases into the current GND. For example, for Franz Kafka the nationality given by the GND is Tschechische Republik (XA-CZ); Österreich (XA-AT); Jüdischer Kulturkreis (Repräsentanten des jüdischen Kulturkreises, die nicht an den Staat Israel gebunden sind) (XY). In this case, the birth place – Prague – is mentioned, but for other authors the GND-entry is sparser with no such information. Furthermore, country borders have changed historically, and writers changed their country of residence (and even language). As such, most authors, that are not “only” German have more than one nationality attributed by the GND.
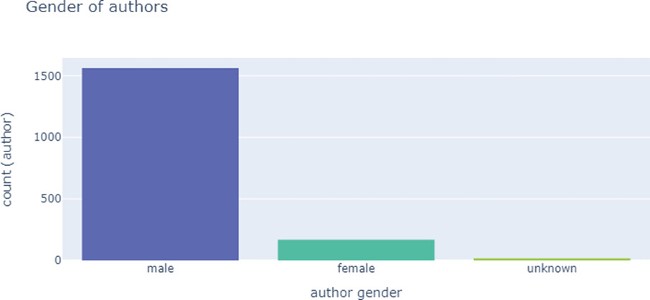
Author gender was recorded by a binary distinction of male and female. The GND assigns N=1,748 authors gender labels as follows: n=1,562 male, n=169 female. For n=17 authors there was no gender given by the GND and it is hard to determine, e.g. because they wrote under a pseudonym:
Browsing the corpus in TextGrid Repository
For technical reasons (TextGrid backend), the corpus data is internally structured by 106 ‘collections’. Each collection consists of 400 randomly sampled texts. Thus, for browsing the corpus, we highly recommend to avoid directly addressing the internal structure (the collections). Instead please use the facets or fulltext queries of the TextGrid project Kolimo+. To do that click on Search within this project at the top of this website. This enables a full text search of all texts (regardless of collection) over the entire Kolimo+ project. Also, the different facets appear at the sidebar to select specific sub-corpora.
The following facets are searchable:
| Facet | Description |
|---|---|
| Author | first and last name of the author |
| Timeslot | grouped into slots of 20 years by birth year of author |
| Author's gender | author gender |
| Genre | text class by TextGrid (prose, non-fiction, other) |
| Size | size of the text following the ELTeC guidelines |
| Language | language of the text |
The fulltext search and the facet search can be combined, e.g. if you wish to search for a specific word in all works of a given author. For more information about using the TextGrid query functions, please consult the documentation. You can download all texts matching your criteria by selecting Download all.
You can also assess full text view and read the works online, if you go down to the work level of the TextGrid schema. Here it is also possible to download single texts as a xml-file in the TEI-schema by choosing either the metadata, the text as txt-file, as html-file, or as an epub-file.
The XML files
The XML files follow the TEI schema DTAbf (German Text Archive “DTA Basisformat”, see here). The basic structure of the files is a teiHeader- element with all metadata and followed by a text-element with the content of the work. The teiHeader-element is unified, but since Kolimo+ was aggregated from three large online repositories, the text-element still follows the original source's style. Important note: the XML contains additional metadata fields that are not searchable by the TextGrid infrastructure.
If you selected the texts you wish to work with, you can either download the XML-files in the DTA-TEI schema or txt-files with just the content of the work in a zip folder. Epub and html is only available for single texts, not for a batch download.
For ease of use the full set of metadata is also available in a csv-file, if you wish to do some metadata analysis in a programming language of your choice.
The following metadata is only available in the files:
| Matadatum | Description |
|---|---|
| nationality | A sorted list of nations from the GND. |
| translation status | Whether the text is German language original or a translation from a different language. |
| original classifications | The original genre classification from the three original sources. |
| publication year | If from the original source available, the date of publication is also included. |
| date of birth | The year of birth of author. |
| date of death | The year of death of author. |
| number of tokens | The number of tokens of the text. |
| source | The online source from which the text was gathered. |
| Kolimo genre | An alternative classification of text size, which is focused on novels. |
| Kolimo ID | The ID of the text and also the filename in the corpus. |
| Kolimo date | The approximation of the publication date by using author’s date of birth and adding 20 years. |
| Flesh-Reading Ease | The value for the Flesh Reading Ease index for reading difficulty of a text. Calculated with the R package koRpus. |
| nWS1 | The value for the 1. Neue Wiener Sachtextformel for reading difficulty of a text. Calculated with the R package koRpus. |
| nWS2 | The value for the 2. Neue Wiener Sachtextformel for reading difficulty of a text. Calculated with the R package koRpus. |
| nWS3 | The value for the 3. Neue Wiener Sachtextformel for reading difficulty of a text. Calculated with the R package koRpus. |
| nWS4 | The value for the 4. Neue Wiener Sachtextformel for reading difficulty of a text. Calculated with the R package koRpus. |
| LIX | The value for Björnsson's Läsbarhetsindex for reading difficulty of a text. Calculated with the R package koRpus. |
| RIX | The value for the Anderson's Readability Index for reading difficulty of a text. Calculated with the R package koRpus. |
| KuntzschsText-Redundanz-Index | The value for Kuntzsch's Text-Redundanz-Index for reading difficulty of a text. Calculated with the R package koRpus. |
| TuldavasTextDifficultyFormula | The value for the Tuldava's Text Difficulty Formula for reading difficulty of a text. Calculated with the R package koRpus. |
| Wheeler-Smith | The value for the Wheeler-Smith Score for reading difficulty of a text. Calculated with the R package koRpus. |
Citation suggestion
If you use Kolimo+ in your research, please cite the following references:
Corpus of Literary Modernity (Kolimo+) in TextGrid Repository (2025). Edited by Berenike Herrmann, Daniel Kababgi, and Gerhard Lauer . Version 1.0.0, based on Kolimo beta release (2018). TextGrid Repository. https://textgridrep.org/project/TGPR-13b65bd8-2b52-4c43-175b-68dcf7a01c06.
Herrmann, J. Berenike, und Gerhard Lauer. 2018. „Korpusliteraturwissenschaft. Zur Konzeption und Praxis am Beispiel eines Korpus zur literarischen Moderne“. Osnabrücker Beiträge zur Sprachtheorie (OBST) 92:127–56.
Beek, Alan Lena van, and Berenike Herrmann. 2022. “KOLIMO+: Optimierung und Offene Publikation des Korpus der Literarischen Moderne“.” Poster presented at the Text+ Plenary 2022, Mannheim.
Herrmann, Berenike, and Gerhard Lauer. 2016a. “Das ,Was-Bisher-Geschah’ von KOLIMO. Ein Update zum Korpus der Literarischen Moderne.” In DHd 2017: Digitale Nachhaltigkeit. Konferenzabstracts, 107–10. Bern. https://zenodo.org/records/3684825.
———. 2016b. “KAREK. Building and Annotating a Kafka/Reference Corpus.” In Digital Humanities 2016: Conference Abstracts, 552–53. Leipzig. http://dh2016.adho.org/abstracts/427.